Steps to avoid over use and misuse of ML in clinical research Review
Steps to avoid over use and misuse of ML in clinical research Review
Information
link: https://www.nature.com/articles/s41591-022-01961-6
Introduction
- The lackluster performance of many machine learning (ML) systems in healthcare
- has been well documented.
- In healthcare, AI algorithms can even perpetuate human prejudices such as
- sexism and racism when trained on biased datasets
Box 1 | Recommendations to avoid overuse and misuse of AI in clinical research
- Whenever appropriate, (predefined) sensitivity analyses
- using traditional statistical models should be presented alongside ML models.
- Whenever appropriate, (predefined) sensitivity analyses
- Protocols should be published and peer reviewed whenever possible, and
- the choice of model should be stated and substantiated.
- Protocols should be published and peer reviewed whenever possible, and
- All model performance parameters should be disclosed and, ideally,
- the dataset and analysis script should be made public.
- All model performance parameters should be disclosed and, ideally,
- Publications using ML algorithms should be accompanied by disclaimers
- about their decision-making process, and
- their conclusions should be carefully formulated.
- Publications using ML algorithms should be accompanied by disclaimers
- Researchers should commit to developing interpretable and transparent ML algorithms
- that can be subjected to checks and balances.
- Researchers should commit to developing interpretable and transparent ML algorithms
- Datasets should be inspected for sources of bias and
- necessary steps taken to address biases.
- Datasets should be inspected for sources of bias and
- The type of ML technique used should be chosen taking into account
- the type, size and dimensionality of the available dataset.
- The type of ML technique used should be chosen taking into account
- ML techniques should be avoided when dealing with
- very small, but readily available, convenience clinical datasets.
- ML techniques should be avoided when dealing with
- Clinician–researchers should aim to procure and utilize
- large, harmonized multicenter or international datasets with high-resolution data, if feasible.
- Clinician–researchers should aim to procure and utilize
- A guideline on the choice of statistical approach,
- whether ML or traditional statistical techniques, would
- aid clinical researchers and highlight proper choices
- A guideline on the choice of statistical approach,
Failure to replicate
- At the beginning of the COVID-19 pandemic,
- the development of ML algorithms to estimate the probability of infection was hot.
- These algorithms based their predictions on various data elements
- captured in electronic health records, such as chest radiographs
- These algorithms based their predictions on various data elements
- Despite their promising initial validation results,
- the success of numerous artificial neural networks trained on chest X-rays
- were largely not replicated when applied to different hospital settings,
- in part because the models failed to learn or understand the true underlying pathology of COVID-19
- the success of numerous artificial neural networks trained on chest X-rays
- These ML algorithms were
- not explainable and,
- were inferior to traditional diagnostic techniques such as RT-PCR,
- obviating their usefulness.
- More than 200 prediction models were developed for COVID-19,
- some using ML, and
- virtually all suffer from poor reporting and high risk of bias
- the development of ML algorithms to estimate the probability of infection was hot.
Avoiding overuse
- The term ‘overuse’ refers to
- the unnecessary adoption of AI or advanced ML techniques
- where alternative, reliable or superior methodologies already exist.
- In such cases, the use of AI and ML techniques is
- not necessarily inappropriate or unsound,
- but the justification for such research is unclear or artificial:
- for example, a novel technique may be proposed that delivers no meaningful new answers.
- A high AUC is not necessarily a mark of quality,
- as the ML model might be over-fit (Fig. 1).
- Figure 1 Model fitting
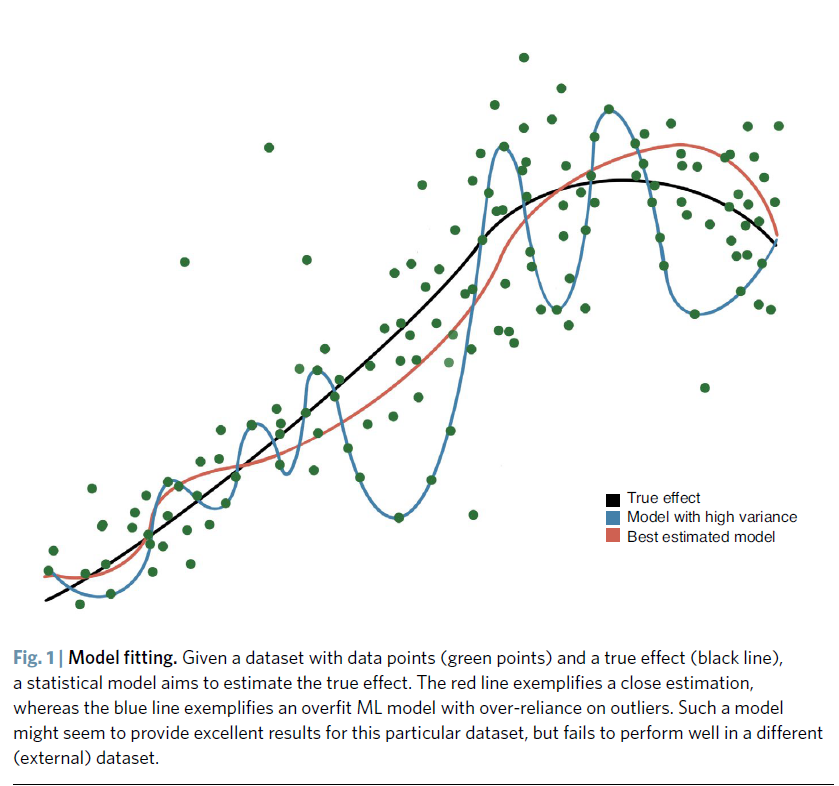
- When a traditional regression technique is applied and compared against ML algorithms,
- the more sophisticated ML models often offer
- only marginal accuracy gains,
- presenting a questionable trade-off between model complexity and accuracy
- Even very high AUCs are no guarantees of robustness,
- as an AUC of 0.99 with an overall event rate of <1% is possible, and
- would lead to all negative cases being predicted correctly,
- while the few positive events were not
- many simple medical prediction problems are inherently linear,
- with features that are chosen because they are known to be strong predictors,
- usually on the basis of prior research or mechanistic considerations.
- In these cases, it is unlikely that
- ML methods will provide a substantial improvement in discrimination
- modest improvements in medical prediction accuracy are
- unlikely to yield a difference in clinical action
- ML techniques should be evaluated against traditional statistical methodologies
- before they are deployed.
- If the objective of a study is to develop a predictive model,
- ML algorithms should be compared to a predefined set of traditional regression techniques
- for Brier score
- (an evaluation metric similar to the mean squared error, used to check the goodness of a predicted probability score)
- https://data.library.virginia.edu/a-brief-on-brier-scores/
- discrimination (or AUC) and calibration.
- for Brier score
- The model should then be externally validated
- ML algorithms should be compared to a predefined set of traditional regression techniques
Rationalize usage
- Researchers should start any ML project with
- clear project goals and
- an analysis of the advantages that AI, ML or conventional statistical techniques
- deliver in the specific clinical use case
- If the objective of a study is to develop a new prognostic nomogram or predictive model,
- there is little evidence that ML will fare better than traditional statistical models
- even when dealing with large and highly dimensional datasets
- there is little evidence that ML will fare better than traditional statistical models
- If the purpose of a study is to infer a causal treatment effect of a given exposure,
- many well-established traditional statistical techniques, such as
- structural equation modelling, propensity-score methodology, instrumental variables analysis a regression discontinuity analysis,
- yield readily interpretable and rigorous estimates of the treatment effect
- many well-established traditional statistical techniques, such as
Avoiding misuse
- the term ‘misuse’ connotes more egregious usages of ML,
- ranging from problematic methodology that engenders spurious inferences or predictions,
- to applications of ML that endeavor to replace the role of physicians
- in situations which should still require a human input
- Indiscriminately accepting an AI algorithm
- purely based on its performance,
- without scrutinizing its internal workings,
- represents a misuse of ML19, although
- it is questionable to what extent every clinician decision is robustly explainable
- Many groups have called for explainable ML or the incorporation of counterfactual reasoning
- in order to disentangle correlation from causation
- The notion of a ‘black box’ that underpins clinical decision-making
- is an antithesis to the modern practice of medicine and
- is increasingly inaccurate,
- given the growing armamentarium of techniques such as
- saliency maps and generative adversarial networks
- that can be used to probe the reasoning made by neural networks
- given the growing armamentarium of techniques such as
- Researchers should commit to developing ML models that are
- interpretable, with their reasoning standing up to scrutiny by human experts, and
- to sharing de-identified data and scripts
- that would allow external replication and validation
Data constraints
- Usage of ML in spite of data constraints, such as biased data and small datasets,
- is another misuse of AI.
- Deep learning techniques are known to require large amounts of data,
- but many publications in the medical literature
- feature techniques with much smaller sample and feature-set sizes than
- are typically available in other technological industries.
- Meta’s Facebook trained its facial recognition software using photos from more than 1 billion users;
- autonomous automobile developers use billions of miles of road traffic video recordings from hundreds of thousands of individual drivers in order to develop software to recognize road objects; and
- DeepBlue and AlphaGo learn from millions or billions of played games of chess and Go
- In contrast, clinical research studies involving AI generally
- use thousands or hundreds of radiological and pathological images, and
- surgeon–scientists developing software for surgical phase recognition
- often work with no more than several dozen surgical videos
- These observations underscore
- the relative poverty of big data in healthcare and
- the importance of working toward achieving sample sizes ike those that have been attained in other industries, as well as
- the importance of a concerted, international big-data sharing effort for health data.
- but many publications in the medical literature
Human–machine collaboration
- The respective functions of humans and algorithms in delivering healthcare are not the same
- ML algorithms can complement, but not replace,
- physicians in most aspects of clinical medicine,
- from history-taking and physical examination
- to diagnosis, therapeutic decisions and performing procedures.
- physicians in most aspects of clinical medicine,
- Clinician–investigators must therefore
- forge a cohesive framework whereby big data propels
- a new generation of human– machine collaboration
- forge a cohesive framework whereby big data propels
- ML algorithms can complement, but not replace,
- ML applications are likely to exist as
- discrete decision-support modules to support specific aspects of patient care,
- rather than competing against their human counterparts
- Human patients are likely to want
- human doctors to continue making medical decisions,
- no matter how well an algorithm can predict outcomes.
- ML should, therefore, be
- studied and implemented as
- an integral part of a complete system of care.
- studied and implemented as
- The clinical integration of ML and big data is poised to improve medicine.
- ML researchers should recognize the limits of their algorithms and models
- in order to prevent their overuse and misuse,
- which would otherwise sow distrust and cause patient harm
- in order to prevent their overuse and misuse,
- ML researchers should recognize the limits of their algorithms and models
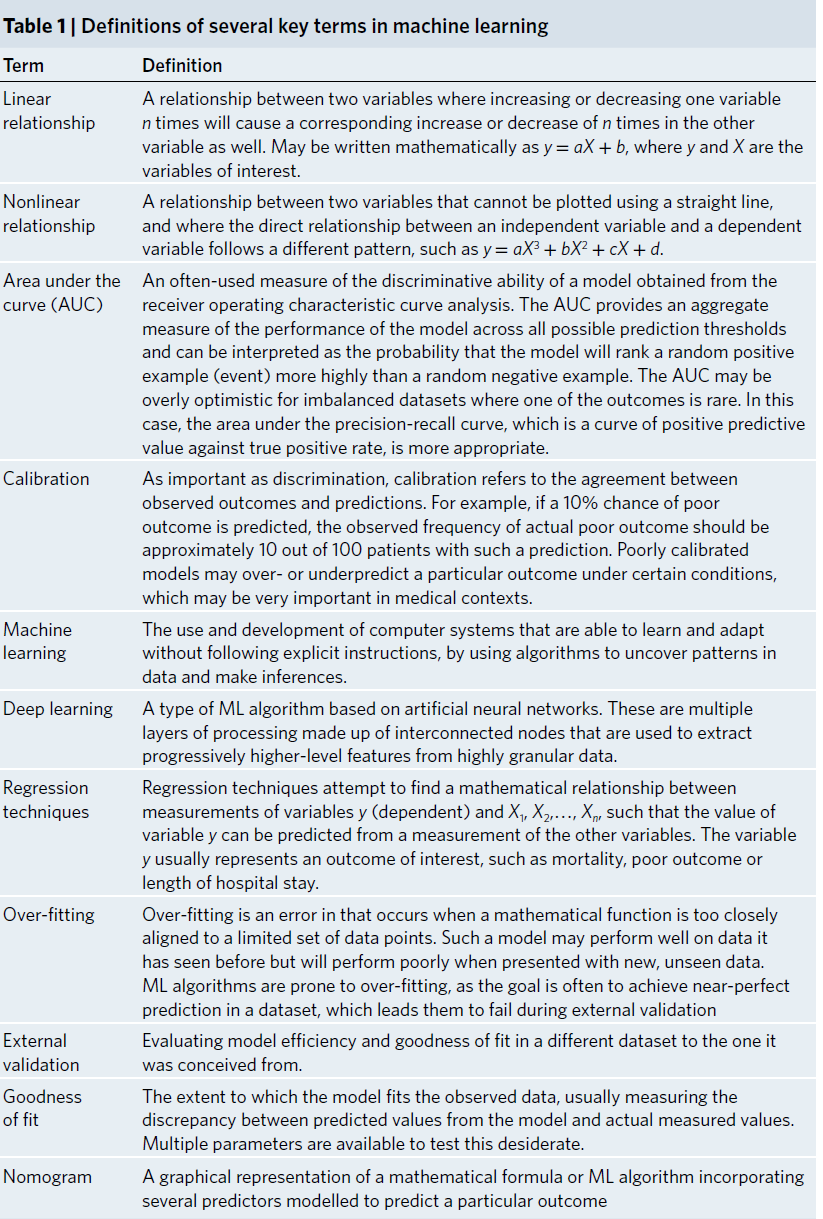
Table 1: Definitions of several key terms in machine learning
This post is licensed under CC BY 4.0 by the author.