통계적 유의성 vs 임상적 유의성
통계적 유의성 vs 임상적 유의성

예전에 컬러링한 Heart 도안..문제의 핵심(Heart of the problem)에 대해 생각해보자는 취지에서 골라봄
Statistical significance vs Clinical significance
Biostatistician으로 식약처에서 임상통계 심사업무를 하면서 이 두 개념에 대한 설명을 자주 하기도 했고 고민을 많이 했던 이슈이기도하다.
비열등성 검정처럼 어떤 특정한 기준값(e.g, 비열등성 마진)이 해당 임상시험 결과에서 만족이 되었는 지를 보는 경우도 있지만, 대부분의 경우 임상시험의 결과가 ‘통계적으로 유의’ 했다고 표현하는 것은, 시험군 vs 대조군의 평균 차이던, 단일군에서의 before vs after의 전후 차이 등이 통계 검정 결과 ‘0’과 ‘유의하게(significantly)’ 차이가 났음이 p-value가 0.05 미만으로 나오거나 차이에 대한 95% 신뢰구간이 0을 포함하지 않았던 가 등으로 입증되었음을 의미한다.
임상적 유의성은 일단 이 ‘차이’가 ‘차이가 없음’을 의미하는 0과는 다르다(크거나 작아서..)는 것이 ‘통계적’으로 확인(e.g, p < 0.05 또는 95% CI LB > 0 )되고 나서 이 차이가 임상적으로도 의미가 있을 정도로 크면 ‘임상적으로 의미’가 있다, 즉 효과가 있다라는 의미이다.
그래서 어떤 임상시험 결과가 ’통계적으로 유의’했다는 표현만으로는 그 결과가 ‘임상적으로도 유의’한 지를 알 수 없고, 임상적으로 의미가 있는 지를 가늠해 보려면 단순히 분석 결과의 p-value가 0.05 미만인지만을 확인할 것이 아니라 분석 결과의 평균과 그 값에 대한 95% 신뢰구간(하한, 평균, 상한)을 함께 제시해서 판단해야 한다.
통계적 유의성을 판정하는 척도인 p-value는 특히나 sample 수가 증가할 수록, 작아지기 때문에 단순히 통계적 유의성만을 보이려면 100명이든 500명이든 무조건 최대한 많은 피험자를 모집해서 임상시험을 하면 된다.
효과가 불명확한 신약이나 새로운 의료기기에 대해 그런 식으로 사람에게 이런 저런 처치를 하는 건 ‘비윤리’적이고 비용도 많이 들기 때문에 임상시험에서 통계적인 사항들을 고려하여 sample size를 계산하는 것은 매우 중요하다.
다이어트약 예시를 설명할 때 자주 들곤 한다. 가령 다이어트 효과를 보기 위해서 시험군(다이어트약 복용) vs 대조군(placebo 약 복용)을 나누어서 한달 뒤에 체중 감소량의 차이를 비교할 때 시험군과 대조군의 이 차이 자체는 5kg이더라도 sample size가 너무 작아 5명 vs 5명의 차이를 비교한 상황에서는 p-value는 0.05 보다 커서 통계적 유의성을 못 보일 수도 있고 차이 자체는 0.1 kg이더라도 10000명 vs 10000명을 비교한 경우에는 p-value는 0.05보다 작더라도 0.1 kg의 차이가 임상적으로 의미가 없는 값일수도 있고 그렇다.
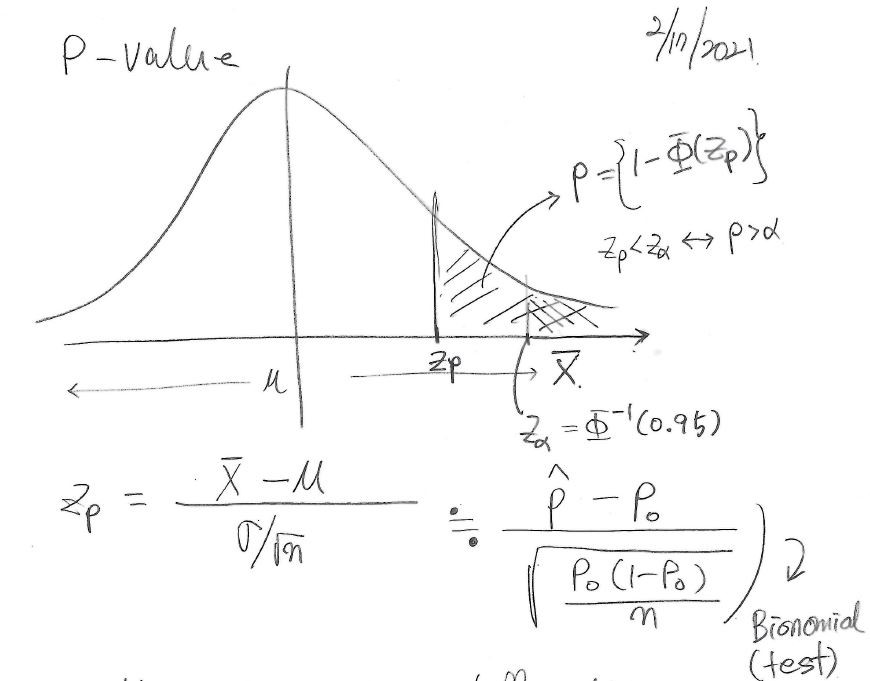
Z 값과 표준정규분포…(image from Amang Kim님)
왜 이런 ‘비직관’적인 결과가 나오냐면, 해당 표본에서의 개별 결과값이 평균과 비교해서 변하는 정도(variability)를 나타내는 표준 오차(standard error)는 n(sample size)이 커질수록 작아지고, 일종의 확률값인 p-value 값을 구할 때 사용하는 통계량(statistic)인 z(종 모양 분포라고 흔히들 알고 있는 표준정규분포를 따름)는 또 분산이 작을수록 커지고 z값이 커질 수록 p-value는 작아지고… 이런 관계가 수식적으로 성립해서 그렇다.
임상통계 심사 업무할 적에 대조군이 sham device나 무처치 no treatment로 설정된 경우에는 통계적 유의성, 즉 차이가 통계적으로 유의하게 0보다는 크게 나더라 하는 것에 더해 MCID, minimally clinical important difference 등을 고려해 임상적 유의성 기준에 대한 설정이 있어야 하는데 워낙 기기가 다양하고 reference는 부족해서 고민을 많이 했었었다.